

2024 Q1 Most Exciting LLM-powered Projects
Following up on the list of 2023’s most exciting projects, here is the list of the most useful, innovative and exciting LLM-powered projects I found in 2024 Q1.
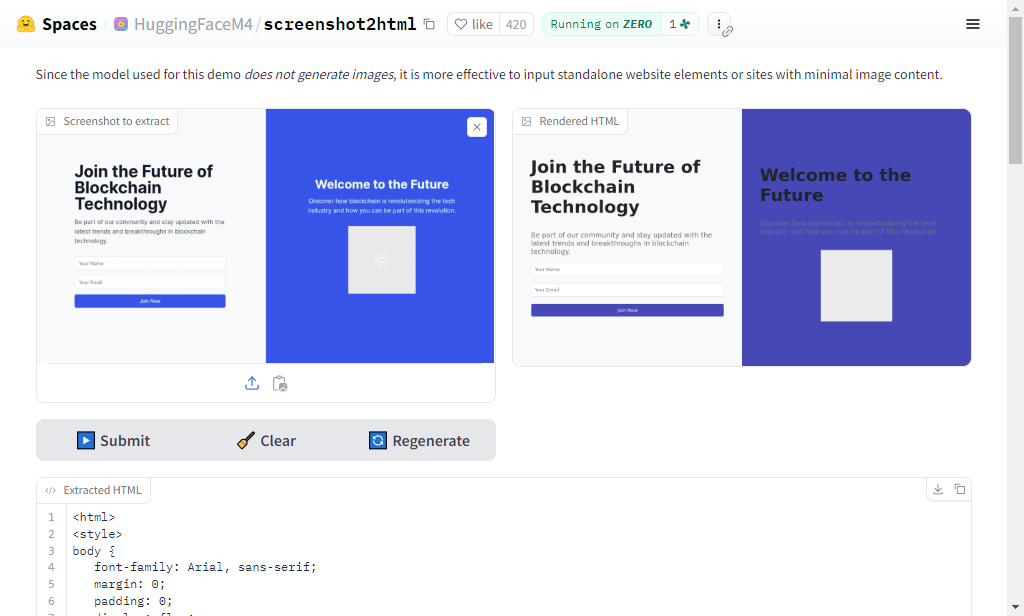
Screenshot2HTML 🖼️📲
Websight is a dataset of 823,000 pairs of web page images and their corresponding HTML/CSS code, created by the HuggingFace team. In this space, you can try out the model that converts images of websites to html pages.
Machine Learning Engineering Open Book 📖
Are you interested in learning how to train large language models and multi-modal models effectively and efficiently? If so, you might want to check out the Machine Learning Engineering Open Book1, a collection of methodologies and best practices created by Stas Bekman, a senior ML engineer at Contextual.AI. This book covers topics such as hardware components, performance optimization, fault tolerance, debugging, reproducibility, and more. It also includes scripts and commands that you can use to solve common problems and challenges in ML engineering. Whether you are a beginner or an expert, you will find something useful and insightful in this book.
InstantID: Zero-shot identity-preserving model 🧑🏼🎨
InstantID is a project that allows you to generate realistic and diverse images of web pages, characters, and faces while preserving their identity. It uses a novel zero-shot identity-preserving generation method that does not require any training or fine-tuning. You can try out the model online or download it from Huggingface. You can also find the technical report, scripts, and commands on the project’s GitHub page2. InstantID is created by Qixun Wang and his collaborators from Contextual.AI. Take a look at the images I created from the photo on the right.



Ollama: Run LLMs from your desktop 🖥️
Ollama (35K Github stars) is an open-source framework that empowers you to run large language models (LLMs) like Llama 2 and Mistral directly on your local machine. It provides a user-friendly API for setting up, managing, and interacting with these powerful language models, enabling you to leverage their capabilities for tasks like text generation, translation, and code completion. Whether you’re a developer looking to experiment with LLMs or a researcher exploring their potential, Ollama offers a flexible and accessible platform to unlock the power of language models on your terms.
DepthAnything: Convert image to a depth map 📐
Depth-Anything tackles monocular depth estimation, predicting the distance to every pixel in an image using only a single camera. It builds upon a large-scale unlabelled dataset, allowing the model to learn from vast amounts of information without manual depth annotations. This approach surpasses previous methods, achieving impressive performance on both indoor and outdoor scenes. Additionally, the core encoder in Depth-Anything can be fine-tuned for high-level perception tasks like semantic segmentation, demonstrating its flexibility and potential for various applications. Check out the demo.

Langgraph 🦜 🕸️
Tired of building linear chatbots and applications? Enter LangGraph, a library from the LangChain team that unlocks the true potential of Large Language Models (LLMs) for complex, multi-step tasks. Imagine building applications where multiple AI “actors” work together, like a team of experts, cycling through information, making decisions, and taking actions. LangGraph makes this possible, inspired by powerful frameworks like Pregel and Apache Beam. Think building a web navigator that can not only browse, but also analyze and summarize content, or a chatbot that can hold a nuanced conversation that adapts to your needs. If you’re ready to push the boundaries of LLM applications, LangGraph is your launchpad. So grab your coding tools and get ready to explore the exciting world of stateful, multi-actor AI!
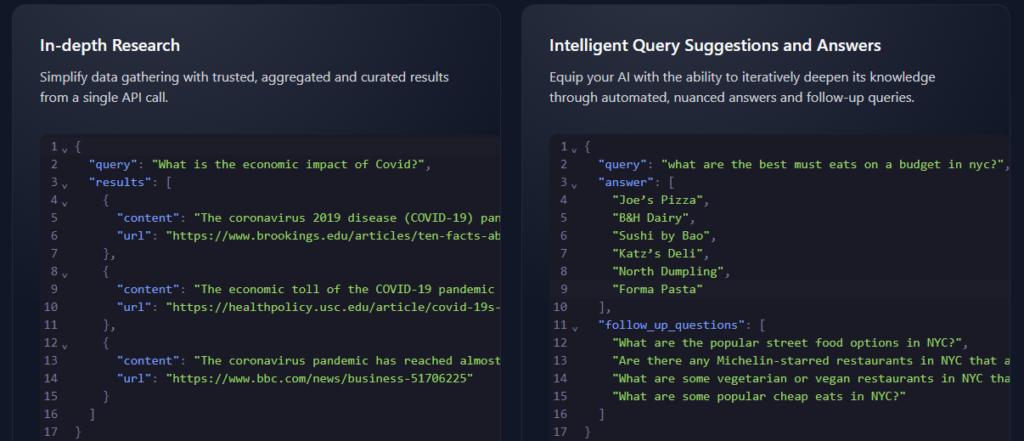
Tavily Search AI 🔍
Tavily is an AI-powered research platform designed to streamline the process for both humans and AI agents. It offers two main products: Tavily Search, a search engine optimized for large language models (LLMs) that provides factual, efficient, and persistent results; and GPT Researcher, an open-source tool that automates online research tasks. Tavily claims to take care of everything from accurate source gathering to result organization, aiming to save users significant time and effort compared to traditional research methods. While some users have reported instability issues, Tavily touts its flexibility and ability to tailor searches to specific needs, making it a potential asset for researchers and developers working with AI.
fabric 🦾
Fabric, an open-source framework, aims to augment humans using AI. Created by Daniel Miessler, it provides a universally accessible layer of AI for enhancing everyday life and work. The philosophy behind Fabric is that AI magnifies human creativity, and its purpose is to solve human problems. The framework breaks down challenges into components, applying AI to each piece individually. Notably, Fabric introduces Markdown-based Patterns—readable and editable AI prompts—to help users integrate AI seamlessly. These Patterns cover diverse activities, from summarizing academic papers to creating AI art prompts. In essence, Fabric empowers everyone to harness AI’s potential in their daily endeavors.
Ragas: Evaluation of RAG pipelines framework 📐
Evaluating LLM responses is always a challenge and this becomes even more crucial when working with RAG pipelines! This open-source framework uses cutting-edge research to measure how well your “Retrieval Augmented Generation” (RAG) system is performing. No more guesswork – Ragas dives deep into key aspects like factual accuracy, context relevance, and information completeness, giving you a clear picture of your RAG’s strengths and weaknesses. Bonus points: it integrates with your development pipeline for continuous monitoring, making sure your AI wordsmith never misses a beat. So, ditch the confusion and embrace Ragas for RAG evaluation that rocks!
Instructor JS 📋
Instructor-JS is a powerful structured extraction library written in TypeScript. It leverages OpenAI’s function calling API and Zod for typeScript-first schema validation with static type inference. Designed for simplicity, transparency, and control, Instructor-JS enables developers to perform structured extraction tasks effortlessly. Whether you’re a seasoned developer or just starting out, you’ll find Instructor’s approach intuitive and user-centric. It’s a versatile tool that empowers you to extract meaningful information from text data using a combination of powerful technologies. Check out the following video from Jason Liu (the maker of Instructor’s Python version).
NVIDIA Chat with RTX: Personal LLM-powered assistant 🤖
Chat With RTX is a demo app by NVIDIA that empowers users to personalize a GPT large language model (LLM) connected to their own content, including documents, notes, videos, and other data. Leveraging retrieval-augmented generation (RAG), TensorRT-LLM, and RTX acceleration, this application allows users to query a custom chatbot and receive contextually relevant answers. The beauty lies in its local execution on Windows RTX PCs or workstations, ensuring both speed and security. Users can load various file formats, such as text, PDF, DOC/DOCX, and XML, into the library, and even transcribe YouTube videos for querying. Developers can explore the underlying technology through the TensorRT-LLM RAG developer reference project on GitHub, enabling them to create their own RAG-based applications accelerated by TensorRT-LLM. Just make sure to have ~3GB RAM and 40GB of disk space available!
MetaVoice-1B: Text-To-Speech Open-Source LLM 🎙️
MetaVoice-1B: A groundbreaking foundational model for human-like, expressive text-to-speech (TTS). Imagine a TTS system that captures not just words, but also the emotional rhythm and tone in English. MetaVoice-1B, with its impressive 1.2 billion parameters, has been meticulously trained on 100,000 hours of speech. But here’s the kicker: it’s not just about raw power. MetaVoice-1B prioritizes zero-shot cloning for both American and British voices, using a mere 30-second reference audio. And guess what? It can even handle cross-lingual voice cloning with minimal training data—just 1 minute for Indian speakers! Whether you’re a tech enthusiast or a curious linguist, this model is your ticket to emotionally rich, long-form synthesis. Plus, it’s released under the Apache 2.0 license, so go ahead, try the demo, and let your creativity flow!
Gemma: Open-source LLM by Google Gemini 🌟
Google just dropped a treasure chest of open-source gems: the Gemma family of lightweight, state-of-the-art language models. Think lightning-fast text generation, question answering, and summarization, all without needing a supercomputer. Built on the same tech as their big brother Gemini.
Gemma doesn’t just strut its stuff on the cloud. It’s equally performant at home on your laptop, workstation, or Google Cloud. So whether you’re building chatbots, summarizing articles, or plotting world domination (kidding!), Gemma’s got your back. Plus, it adheres to Google’s rigorous standards for safety and responsibility, ensuring you won’t accidentally unleash an AI uprising. So go ahead, give Gemma a spin—your next project might just sparkle a little brighter.
It comes in 2B and 7B parameter versions and both of them support a 8192 token context window. The 7B model reportedly outperforms competitors such as Mistral AI 7B and LLaMa 2 in Human Eval and MMLU tests. Try it out here.
Ideogram.ai: LLM images with correct text 🎨
If you’ve ever tried using GPT to create images, you know the pain of spotting typos. LLMs can tackle complex questions, but they still trip over a few words in pictures. Enter ideogram.ai! This nifty tool crafts images with spot-on text (check out the header image of this article!). Plus, it can even spruce up images generated from input prompts. This is why they also managed to secure a cool $80 million in funding!
Google Magika: Detect file types with deep learning 🔍📂
Magika is a novel AI-powered file type detection tool developed by Google. Leveraging cutting-edge deep learning techniques, it provides remarkable accuracy in identifying various content types within files. The underlying custom Keras model, weighing only about 1MB, enables precise file identification in milliseconds, even on a single CPU. In evaluations with over 1 million files and more than 100 content types (including both binary and textual formats).
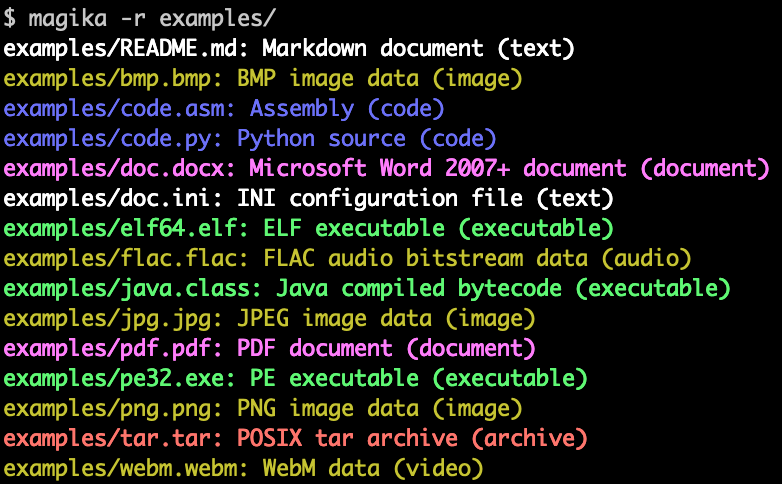
Magika achieves 99%+ precision and recall. It plays a crucial role in enhancing Google users’ safety by routing Gmail, Drive, and Safe Browsing files to the appropriate security and content policy scanners. You can try Magika using the web demo, which runs directly in your browser. Additionally, Magika is available as a Python command-line tool, a Python API, and an experimental TFJS version. It’s open source and continues to evolve.
Continue: Open-source autopilot for VS Code and JetBrains 🚀🔍
Continue, an open-source autopilot for VS Code and JetBrains —the easiest way to code with any LLM (Language Model) if you don’t own GitHub Copilot. Whether you’re a seasoned developer or just starting out, Continue streamlines your coding experience by:
- Providing task and tab autocomplete.
- Answering coding questions.
- Allowing you to highlight and select sections of code, then asking Continue for another perspective.
- Enabling natural language editing—you can instruct Continue to refactor code sections.
- Generating files from scratch, such as Python scripts or React components.
- Supporting experimental local tab autocomplete in VS Code.
- Offering built-in context providers and custom slash commands.
OOTDiffusion: Try on clothes virtually 👗
OOTDiffusion is the official implementation of a fascinating project called “Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on.” Developed by Yuhao Xu, Tao Gu, Weifeng Chen, and Chengcai Chen at Xiao-i Research, this innovative system allows you to virtually try on outfits. Imagine blending fashion and technology seamlessly! The model checkpoints, trained on VITON-HD (768×1024), have already been released, and soon we’ll get the ones trained on Dress Code. If you’re curious, check out the repository and the demo and give it a star if you find it intriguing!

AgentQL: Natural language to interact with web elements 🚀
AgentQL is a powerful tool that lets you build AI agents using a query language for precise web and app automation. AgentQL for Web: This component allows you to locate and interact with web elements through natural language queries. You can easily automate web tasks by expressing your intentions in a human-friendly way. For example, you can query for specific information on a webpage, click buttons, or extract data. Check out the following video for a more detail walkthrough of AgentQL and other technologies used for AI-powered web interactions.
DSPy: Declarative Self-improving Language Programs (in Python) 🚀
DSPy, a framework that flips the script on language models (LMs), is here to revolutionize how we build applications. Say goodbye to endless prompting and hello to programming! Traditionally, using large LMs has been complex and fragile. You’d break down problems into steps, prompt your LM, tweak things, and finetune smaller LMs. But it was messy, and every change meant reworking prompts. DSPy changes the game. First, it separates program flow from LM parameters. Second, it introduces optimizers that compile programs into different instructions, prompts, and weight updates for each LM. The result? Less prompting, higher scores, and a systematic approach to solving hard tasks with LMs.
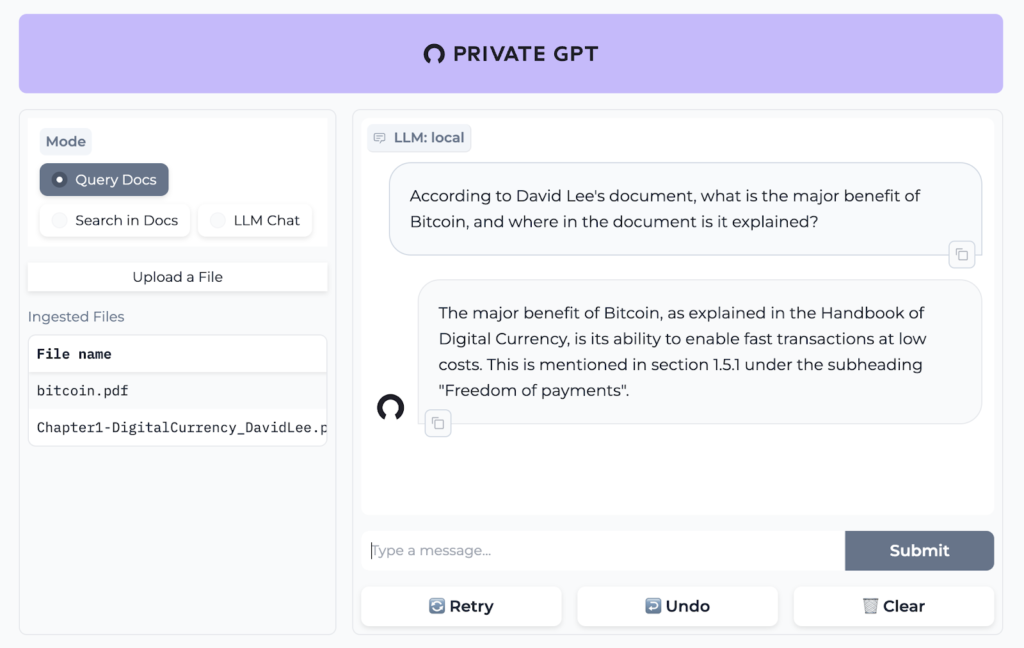
PrivateGPT: Interact with your data 100% privately 🗨️
Private GPT aims to enhance the capabilities of the GPT model. It offers the potential to create a customized and private version of the powerful GPT model, which can be tailored to specific use cases or domains. Developers seeking fine-tuning options or specialized behavior adjustments can benefit from this flexibility. Additionally, having a private GPT variant ensures data privacy and control, which is crucial in scenarios where sensitive information is involved.
Anthropic’s prompt library 💬
Anthropic released a free library filled with prompts designed to supercharge your AI chats. This library offers pre-built prompts for everything from complex data analysis to fun creative writing, all aimed at getting the most relevant and detailed responses from your AI. While designed for their Claude model, these prompts can work wonders with other chatbots that share similar abilities.
Meltemi: LLM for Greek language ☴
The Institute for Language and Speech Processing has introduced ‘Meltemi,’ a large language model dedicated to the Greek language. Meltemi is built on top of Mistral-7B and has been trained on a corpus of high-quality Greek texts. Meltemi stands out as a significant advancement for Greek language technology, offering a tailored solution that understands and generates Greek with a level of fluency and nuance unmatched by more generalized models. Its use makes sense for anyone looking to integrate Greek language processing into their applications, as it’s specifically designed to handle the complexities of Greek syntax and semantics. This focus on a single language allows for more accurate and contextually relevant results, making Meltemi an essential tool for developers and businesses aiming to serve the Greek-speaking market effectively.
It’s available in 2 versions:
- Foundation model Meltemi-7B-v1
- Instruction-tuned derivative, Meltemi-7B-Instruct-v1 which can be used for chat applications

